¿Por qué ahora?

Con el estado actual de la tecnología, se puede entrenar una red neuronal profunda (DNN, por sus siglas en inglés) para que realice tareas específicas, como la detección y reconocimiento de objetos y rostros humanos, reconocimiento de voz, traducción de idiomas, juegos (ajedrez, go, etc.), conducción autónoma de vehículos, monitorización del estado de sensores y toma de decisiones sobre el mantenimiento predictivo de maquinaria, evaluación de imágenes de rayos X de atención sanitaria, etc. Para dichas tareas especializadas, una DNN puede igualar e incluso superar las capacidades humanas.
Por qué emplear inteligencia artificial en el borde
Por ejemplo, los edificios modernos tienen conectados a una red interna multitud de sensores, equipos de climatización, ascensores, cámaras de seguridad, etc. Por motivos de seguridad, latencia o robustez, es más adecuado ejecutar localmente las tareas de inteligencia artificial, en el borde de la red local, y enviar a la nube únicamente los datos anonimizados que sean necesarios para tomar decisiones globales.
Equipos de hardware en el borde
Para implementar una DNN en el borde, se requiere un equipo que disponga al mismo tiempo de suficiente potencia de cálculo y bajo consumo de energía. El desarrollo tecnológico actual ofrece una combinación de una CPU con bajo consumo de energía y acelerador de VPU (SBC con CPU x86 + VPU Intel Myriad X) o CPU + acelerador de GPU (CPU ARM + GPU Nvidia).
La forma más sencilla de poner en marcha una DNN es utilizar el UP Squared AI Vision X Developer Kit, en su versión B. Se basa en un SBC UP Square con un procesador Intel Atom®X7-E3950 con 8 GB de RAM, 64 GB de eMMC, módulo AI Core X con VPU Myriad X MA2485 y cámara USB con una resolución de 1920 x 1080 y enfoque manual. El kit lleva preinstalado Ubuntu 16.04 (kernel 4.15) y el kit de herramientas OpenVINO 2018 R5.
El kit de herramientas contiene aplicaciones de demostración precompiladas en /home/upsquared/build/intel64/Release y modelos ya entrenados en /opt/intel/computer_vision_sdk/deployment_tools/intel_models. Para acceder a la ayuda de cualquier aplicación de demostración, ejecútela en el terminal con la opción -h. Se recomienda inicializar el entorno OpenVINO antes de ejecutar una aplicación de demostración por medio del comando source /opt/intel/computer_vision_sdk/bin/setupvars.sh.
Además del UP Squared AI Vision X Developer Kit, AAEON también ofrece:
1.Módulos basados en la VPU Myriad X MA2485: AI Core X (mPCIe de tamaño completo, 1x Myriad X), AI Core XM 2280 (M.2 2280 B+M key, 2x Myriad X), AI Core XP4/ XP8 (tarjeta PCIE [x4], 4 o 8x Myriad X).
2.Serie BOXER-8000 basada en el módulo Nvidia Jetson TX2.
3.BOXER-8320AI con procesador Core i3-6100U o Celeron 3955U y dos módulos AI Core X.
4.Serie Boxer-6841M con placa base para procesador Intel Core-I o Xeon de sexta o séptima generación para ranura LGA1151 y una ranura PCIe [x16] o dos ranuras PCIe [x8] para la GPU con un consumo de energía máximo de 250 W.
Equipos de hardware para el aprendizaje
Para el entrenamiento de la DNN, se requiere una gran potencia de cálculo. Por ejemplo, en la competición ImageNet de 2012, el equipo ganador utilizó la red neuronal convolucional AlexNet. Se necesitaron 1,4 ExaFLOP = 1,4e6 operaciones TFLOP para el aprendizaje. Dos GPU Nvidia GTX 580, cada una con una potencia de cálculo de 1,5 TFLOP, tardaron 5 o 6 días.La tabla que se muestra a continuación resume el máximo rendimiento teórico de los equipos de hardware.
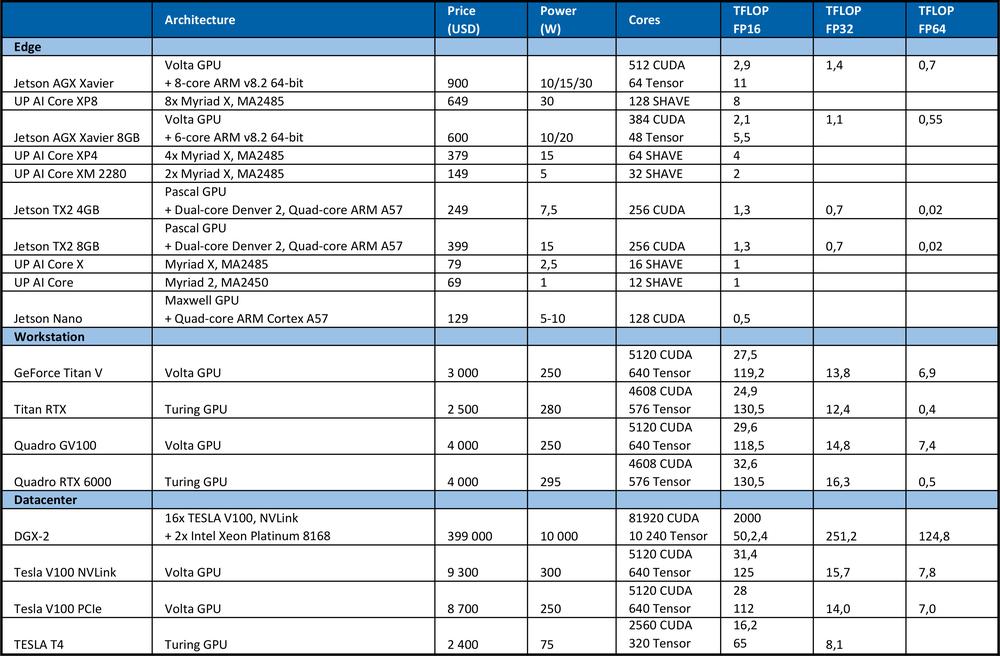
A modo de comparación, el procesador de gama alta Intel Xeon Platinum 8180
● tiene 28 núcleos con dos unidades AVX-512 y FMA en cada uno
●AVX-512 alcanza una frecuencia turbo de 2,3 GHz si todos los núcleos están activos
●cuesta 10 000 USD
Ofrece un rendimiento máximo teórico de: n.º de núcleos * frecuencia en GHz * AVX-512 DP FLOPS/Hz * n.º de unidades AVX-512 * 2 = 2060,8 GFLOPS en precisión doble (DP) → 4.1216 TFLOPS en única (32 bits).
Como se puede apreciar en la tabla anterior, la GPU proporciona un rendimiento muy superior para el aprendizaje de redes neuronales. Cabe señalar que el número de operaciones por segundo no es el único parámetro que afecta al rendimiento de aprendizaje. También influyen en la velocidad de aprendizaje factores como el tamaño de la RAM, la velocidad de transferencia de datos entre la CPU y la RAM, la GPU y la RAM de la GPU o entre GPU.

Software
OpenVINO
El kit de herramientas OpenVINO (red neuronal y de inferencia visual abierta) es un software gratuito que permite la implementación rápida de aplicaciones y soluciones que emulan la visión humana.
El kit de herramientas OpenVINO toolkit:
● Utiliza una CNN (red neuronal convolucional)
●Puede dividir el cálculo entre la CPU Intel, la GPU integrada, Intel FPGA, Intel Movidius Neural Compute Stick y los aceleradores de visión con VPU Intel Movidius Myriad
●Proporciona una interfaz optimizada para OpenCV, OpenCL y OpenVX
●Es compatible con los marcos de trabajo Caffe, TensorFlow, MXNet, ONNX, Kaldi
TensorFlow
TensorFlow es una biblioteca de código abierto para el cálculo numérico y aprendizaje automático. Proporciona una práctica API de front-end para el desarrollo de aplicaciones en el lenguaje de programación Python. No obstante, las aplicaciones generadas con TensorFlow se convierten a código C++ optimizado que se puede ejecutar en diversas plataformas, como CPU, GPU, máquina local, un clúster en la nube, equipos integrados en el borde y similares.
Otro software de utilidad
Jupyter Lab / Notebook
https://jupyter.org/index.html
https://github.com/jupyter/jupyter/wiki/Jupyter-kernels
https://jupyterlab.readthedocs.io/en/stable
Keras
Pandas
MatplotLib
Numpy
Funcionamiento
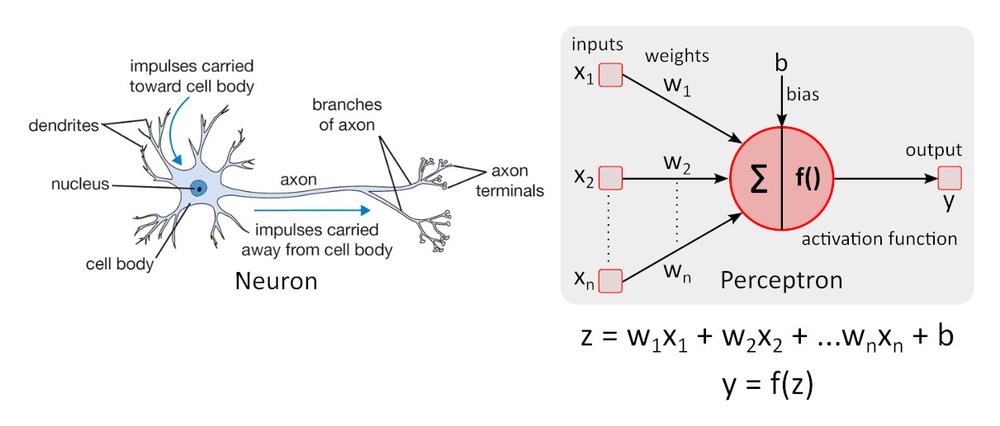
Modelo neuronal simplificado
Modelo neuronal simple: el perceptrón fue descrito por primera vez por Warren McCulloch y Walter Pitts en 1943 y sigue siendo el estándar de referencia en el campo de las redes neuronales.
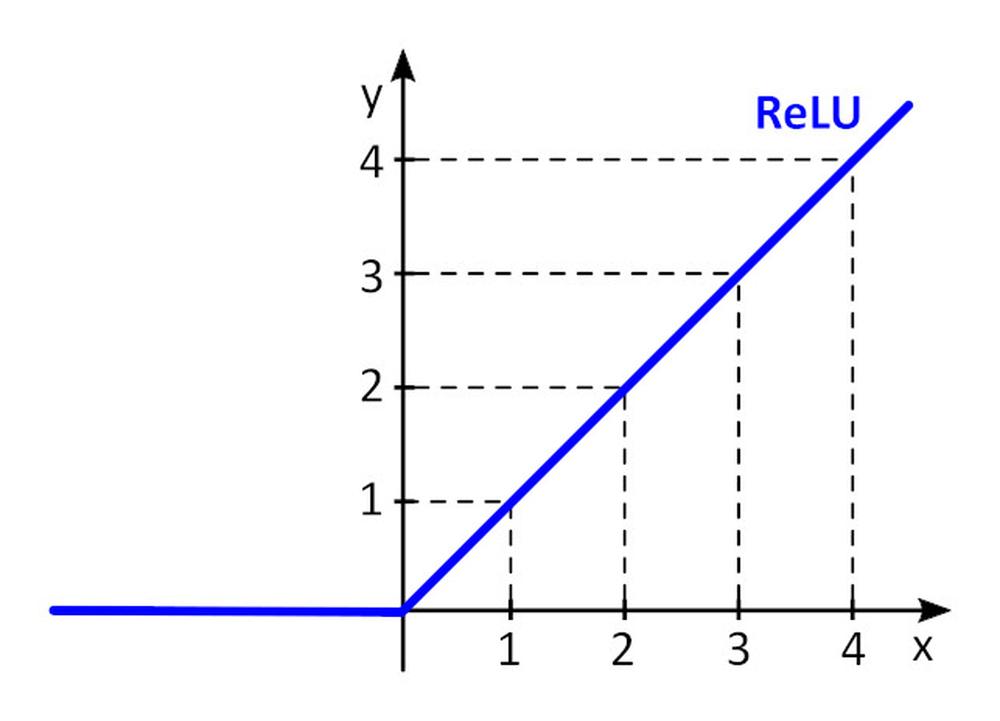
La función de activación f () añade no linealidad a perceptrón. Sin la función de activación no lineal en la red neuronal (NN) de perceptrones, se comportaría como un perceptrón de una sola capa con independencia del número de capas que tuviera, ya que la adición de dichas capas solo proporcionaría otra función lineal. La función de activación que se utiliza más a menudo es la unidad lineal rectificada, ReLU, por sus siglas en inglés.
y = f(x) = máx. (0, x), para x < = 0, y = 0, para x ≥ 0, y = x

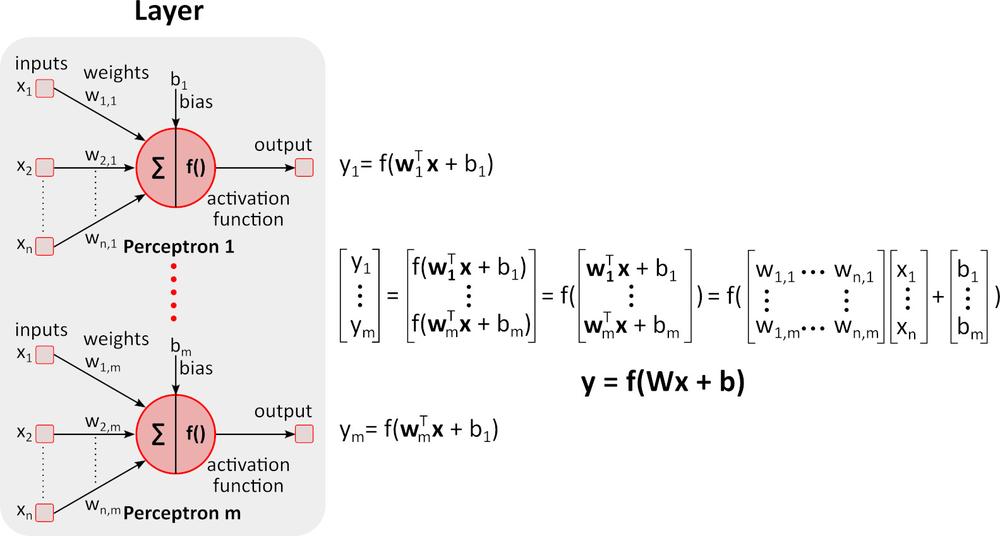
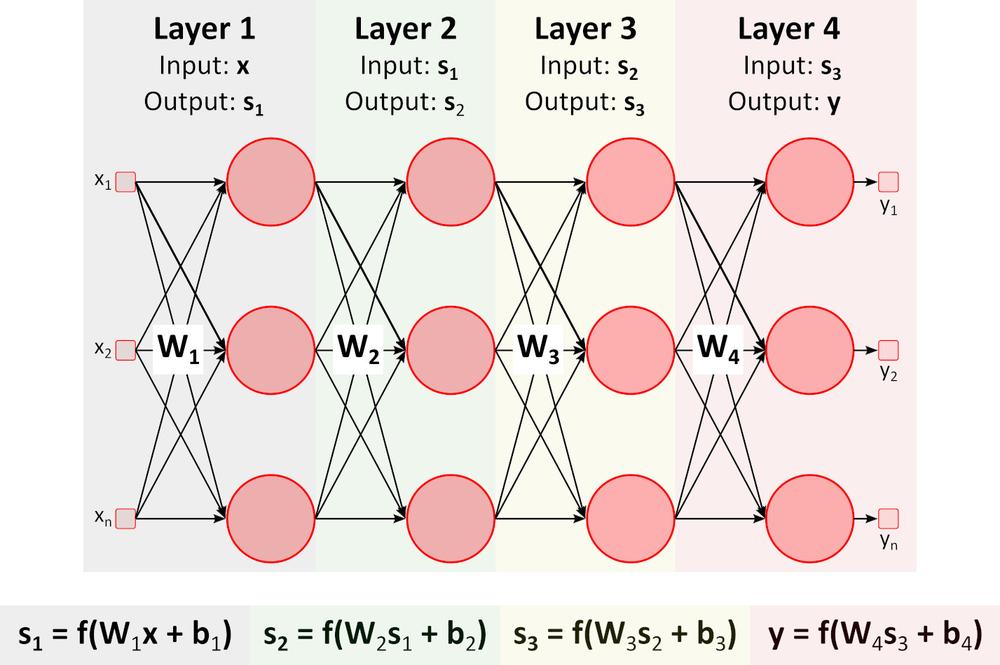
Inferencia (cálculo hacia delante)
La figura anterior muestra una red neuronal profunda (DNN), ya que posee varias capas entre la capa de entrada y la de salida. Como se puede apreciar, la DNN requiere multiplicaciones y sumas de matrices. Los equipos de hardware especialmente optimizados para esta tarea, como las GPU (unidad de procesamiento gráfico) y las VPU (unidad de procesamiento de visión), son mucho más rápidos que las CPU (unidad de procesamiento central, procesador) de uso general y tienen un consumo de energía más bajo.Aprendizaje (cálculo hacia atrás)
Supongamos que queremos enseñar a una DNN a reconocer naranjas, plátanos, manzanas y frambuesas (clases de objetos) en una imagen.
1.Preparamos multitud de imágenes de dichas frutas y las dividimos entre el conjunto de entrenamiento y el conjunto de validación. El conjunto de entrenamiento contiene imágenes y los resultados correctos requeridos de dichas imágenes. La DNN tendrá cuatro salidas o resultados. El primer resultado proporciona una puntuación (probabilidad) de que la fruta que aparece en la imagen sea una naranja; el segundo, lo mismo para un plátano, etc.
2.Se establecen valores iniciales para todas las ponderaciones p_i y sesgos s_i. Se suelen utilizar valores aleatorios.
3.Al pasar la primera imagen por la DNN, la red proporciona puntuaciones (probabilidad) de cada resultado. Digamos que en la primera imagen se muestra una naranja. Los resultados de la red pueden ser y= (naranja, plátano, manzana, frambuesa) = (0,5, 0,1, 0,3, 0,1). La red "indica" que la entrada es una naranja con una probabilidad de 0,5.
4.Se define una función de pérdida (error) que cuantifica la concordancia entre las puntuaciones pronosticadas y las puntuaciones correctas de cada clase. Se suele utilizar la función E = 0,5*suma (e_j) ^2, donde e_j = y_j - y_real_j y j es el número de imágenes que contiene el conjunto de entrenamiento.
5.E_1_naranja = 0,5*(0,5-1)^2=0,125, E_1_plátano = 0,5*(0,1-0)^2 = 0,005 E_1_manzana = 0,5*(0,3-0)^2 = 0,045, E_1_frambuesa = 0,5*(0,1-0)^2 = 0,005 E_1 = (0,125, 0,005, 0,045, 0,005)
6.Se hacen pasar todas las demás imágenes del conjunto de entrenamiento por la DNN y se calcula el valor de la función de pérdida E (E_naranja, E_plátano, E_manzana, E_frambuesa) para todo el conjunto de entrenamiento.
7.Para modificar todas las ponderaciones p_i y sesgos s_i para el siguiente pase de entrenamiento (época), es necesario determinar la influencia que tiene cada parámetro p_i y s_i en la función de pérdida de cada clase. Si el incremento del valor del parámetro genera un incremento del valor de la función de pérdida, es necesario reducir este parámetro y viceversa. ¿Pero cómo se calcula el incremento o reducción de los parámetros que se requieren?
Probemos con un ejemplo sencillo.
Tenemos tres puntos con coordenadas (x, y): (1, 3), (2,5, 2), (3,5, 5). Queremos encontrar la línea y = w.x + s en la que se minimice la función de pérdida E = 0,5*suma (e_j) ^2, donde e_j = y_j – y_real_j, j=1, 2, 3. Para que esta tarea resulte lo más sencilla posible, supongamos que w=1,2 y solo es necesario determinar el valor óptimo de s. Seleccionamos el valor inicial de s = 0.
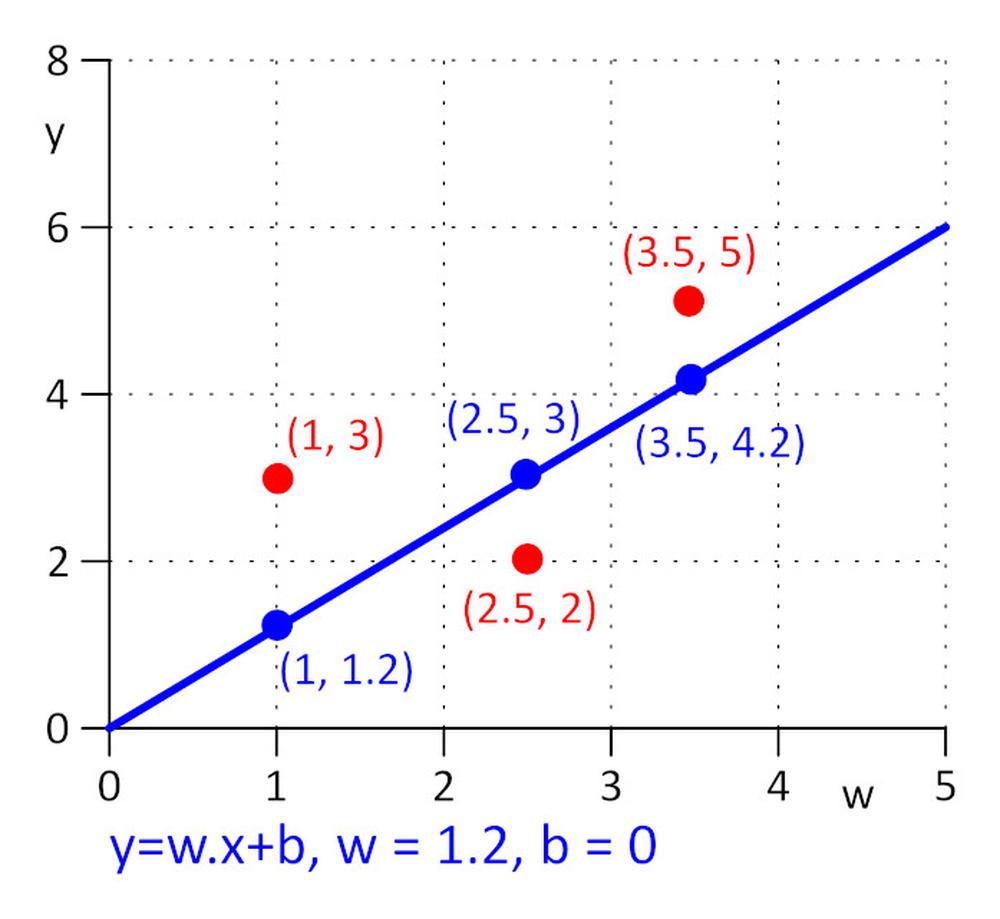
Calculemos la función de pérdida: E = 0,5*suma (e_j) ^2 = 0,5*(e_1^2 + e_2^2 + e_3^2), e_1=1,2*1 + s -3, e_2 = 1,2*2,5 + s – 2, e_3 = 1,2*3,5 + s – 5.
La función de pérdida E es simple. Para encontrar el valor mínimo de E, podemos resolver esta ecuación: ∂E/∂s = 0. Es una función compuesta, para calcular ∂E/∂s, aplicamos la regla de la cadena.
∂E/∂b=0.5*((∂E/∂e_1)*(∂e_1/∂b) + (∂E/∂e_2)*(∂e_2/∂b) + (∂E/∂e_3)*(∂e_3/∂b)) = 0.5*(2*e_1*1 + 2*e_2*1 + 2*e_3*1) = (1.2*1 + b – 3) + (1.2*2.5 + b – 2) + (1.2*3.5 + b – 5) = 0 => b = 0.53333.
En la práctica, cuando el número de parámetros p_i y s_i puede alcanzar o superar el millón, no resulta práctico resolver directamente la ecuación ∂E/∂p_i = 0 y ∂E/∂s_i = 0, sino que en vez de ello se utiliza un algoritmo iterativo.
Hemos empezado con s = 0, el siguiente valor será s_1 = s_0 - η*∂E/∂s, donde η es la tasa de aprendizaje (hiperparámetro) y -η*∂E/∂s es el tamaño del paso. El aprendizaje se detiene cuando el tamaño del paso alcanza un umbral definido; en la práctica, un valor de 0,001 o inferior. Para η = 0,3, s_1 = 0,48, s_2 = 0,528, s_3 = 0,5328, s_4 = 0,53328 y s_5 = 0,5533328. Después de cinco iteraciones, el tamaño del paso desciende a 4,8e-5 y en ese punto detenemos el aprendizaje. El valor de s que se obtiene con este algoritmo es prácticamente igual al valor que se obtiene al resolver la ecuación ∂E/∂s=0.
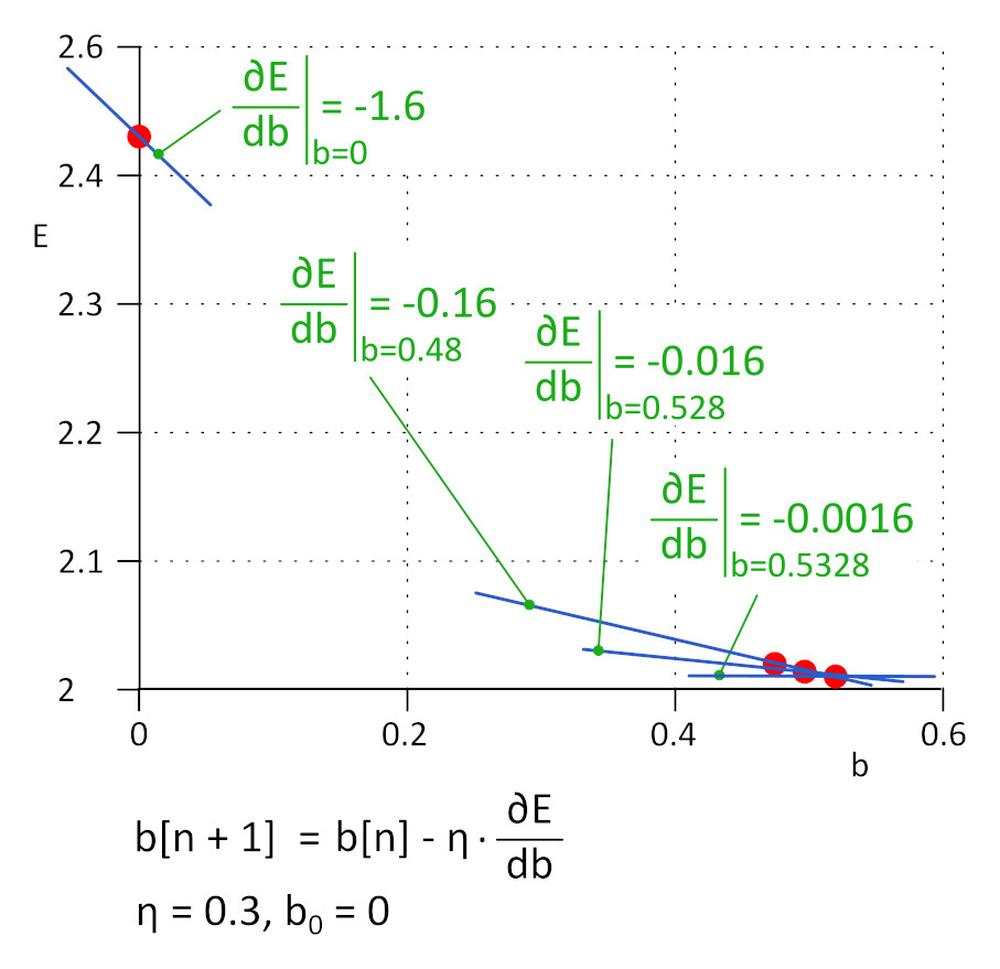
Este método se denomina descenso de gradiente.
La tasa de aprendizaje es un hiperparámetro importante. Si es demasiado baja, se necesitan muchos pasos para determinar el valor mínimo de la función de pérdida; Si es demasiado elevado, puede que el algoritmo falle. En la práctica, se utilizan variaciones mejoradas del algoritmo, como Adam.
8.Repetimos los pasos 5 y 6 hasta que el valor de la función de pérdida se reduce hasta el valor requerido.
9. Pasamos el conjunto de validación por la DNN entrenada y evaluamos su precisión.
Actualmente, el aprendizaje de las DNN es un trabajo altamente experimental. Se conocen muchas arquitecturas de DNN y cada una es adecuada para una serie de tareas específicas. Cada arquitectura de DNN cuenta con su propio conjunto de hiperparámetros que influyen en el comportamiento de la DNN. Ármese de paciencia; el resultado no tardará en llegar.
Si desea obtener más información sobre los productos de AAEON, no dude en ponerse en contacto con nosotros en el correo aaeon@soselectronic.com
No se pierda estos artículos
¿Le gustan nuestros artículos? ¡No se pierda ninguno! No tiene que preocuparse de nada; nosotros dispondremos el envío por usted.




